실제로 전개해보면 다음 식이 도출됩니다([식 5.13]으로 이끄는 과정은 생략합니다).
– p172, 5.6.1 Affine 계층, 밑바닥부터 시작하는 딥러닝
아니! 그걸 생략하면 어떡해요!!
“밑바닥부터 시작하는 딥러닝”을 읽으면서 딥러닝의 개념을 잡는데 많은 도움을 받고 있지만 굳이 단점을 들자면 주요한 공식 들에 대해 설명하지 않고 그냥 넘어 가버리는 경우가 가끔 있다. 위에서 말하는 [식 5.13]은 back propagataion에서 입력에 대한 loss function의 영향과 weight에 대한 loss function의 영향을 계산하는 다음 식을 의미한다.
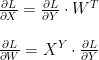
이 식이 도대체 어떻게 유도된 것인지 이리 저리 찾다가 마침 이 부분을 자세히 설명해 주고 있는 미국 어느 대학(!)의 훌륭한 문서(Backpropagation for a Linear Layer, Justin Johnson, April 19, 2017)를 발견했다. 이 포스팅은 해당 문서에 대한 나름의 이해를 정리한 것이다.
밑밥 깔기
Matrix인 입력 X, Weight W가 있다고 할 때, 이 둘의 dot product인 Y는 다음과 같은 모습이다.
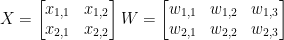

Back propagation을 통해 최종으로 구하고자 하는 것은 입력의 변화에 따른 loss function의 변화량 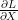
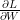
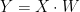
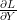

Y의 변화에 따른 Loss function의 변화
여기에서 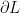

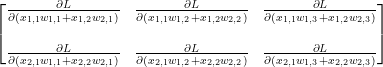
복잡하니까 조금 간단히 다음과 같이 인덱스로 나타내자.
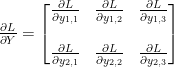
이제, 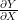

행렬 X의 원소들에 대한 행렬 Y의 편미분
먼저 

각 원소들은 scalar 값인데 그 중 첫번째 원소인 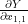
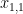
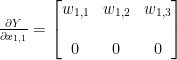
응? 갑자기 이건 뭐냐!
예를 들어 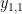


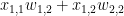

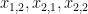

행렬 X에 대한 scalar L의 편미분 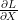

Matrix X의 첫번째 원소는 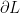
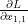
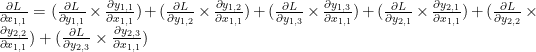
이것도 뭐 딱히 깨끗해 보이진 않지만… 여튼, matrix Y의 각원소들에 대해
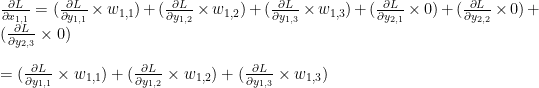
같은 방법을

이것을 matrix의 형태로 나타내면
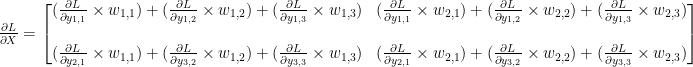
Matrix Y와 W를 구분해 보면
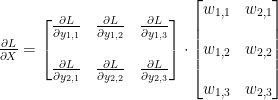
Weight matrix W의 전치행렬(transpose matrix)를 곱하는 것이 되므로,

Weight에 대한 loss function의 변화인 
좋은 글 감사합니다. 잘봤습니다.
다만 올려주신 Backpropagation for a Linear Layer(Justin Johnson, April 19, 2017)에서 자코비안 행렬이 언급되는데, 자코비안 행렬은 비선형변환에서만 해당하는 내용 아닌가요? 갑자기 왜 나온건지 모르겠네요 ㅠ
1st order partial derivative를 자코비안 행렬이라 하기에 여기에서도 맞게 표현되었습니다.
저도 식 5.13에 대해서 한참 찾았는데 이런 자세한 설명이 있다니 너무 감사합니다. 공부하는데 잘 참고하도록 할게요!
안녕하세요? 좋은 글 잘 읽고 있습니다.
“행렬 X의 원소들에 대한 행렬 Y의 편미분” 과 “응? 갑자기 이건 뭐냐!” 사이에 dY/dX 행렬 크기가 2×3 인데 이게 맞는지요?
분모의 x_1,3 과 x_2,3 이 어디서 갑자기 등장했는지 모르겠습니다.
감사합니다.
안녕하세요.
말씀하신 대로 dY/dX행렬의 크기는 입력 행렬 X의 크기인 2×2가 되어야 맞습니다. 입력 행렬에 없는 인덱스 부분은 오류입니다. 알려 주셔서 감사합니다.
넵, 그렇군요!
좋은 글 써 주셔서 잘 배우고 갑니다.
감사합니다!