Remote에서 제공하는 기능을 마치 local system의 function call 처럼 제공 한다는 gRPC의 개념 자체는 1990년대에도 있었던 것이기에 새로울 것은 없지만, 그 위에서 “Subject의 변경이 있을 때 subscriber에게 notify 해주는 Observer Pattern을 어떻게 구현 할 수 있을까?”하는 의문이 들었다.
이 포스팅에서는 gRPC를 이용한 observer pattern의 예제로 server에서 임의의 주식과 그 변동 가격을 client로 notify 해주고 이것을 화면에 출력하는 예제를 작성해 본다. 전체 코드는 https://github.com/litcoder/grpcobsr에서 확인 할 수 있다.
기본적인 gRPC는 client에서 필요한 정보를 server에게 요청해서 그 결과를 돌려받는다. 반면, Observer Pattern은 그 반대로 server 측에서 정보의 변경 사항이 있을 때 이것을 client 측에 알려 주어야 한다.

이를 가능하게 하는 것은 ServerWriteRector와 ClientReadReactor template인데, 이들은 client의 요청에 대해 server가 여러 개의 응답을 비동기적으로 전송하는 이른바 gRPC의 server-side streaming을 구현하는데 가장 핵심이 되는 요소들이다. 우리 예제의 경우 client는 server로 “주식 가격을 알려 주세요”라는 request를 전송하면 ClientReadReactor의 OnReadDone() 함수로 변경된 주식과 가격이 하나씩 들어오는 식이다.
Proto file
주식 정보를 제공하는 proto file은 다음과 같이 정의 한다. 클라이언트가 UpdateStockPrice()를 요청하면 서버가 StockPriceResponse를 여러 개 stream으로 전송해 주는데 그 안에는 각각의 주식의 종목(symbol)과 가격(price) 정보가 담겨져 있다.
syntax = "proto3";
import "google/protobuf/empty.proto";
message StockPriceResponse {
string symbol = 1;
double price = 2;
}
service StockService {
rpc UpdateStockPrice(google.protobuf.Empty) returns (stream StockPriceResponse);
}
StockPriceWriteReactor
StockPriceWriteReactor는 서버에서 동작하는 reactor이다.
class StockPriceWriteReactor
: public ::grpc::ServerWriteReactor<::StockPriceResponse>
{
public:
StockPriceWriteReactor(int evCnt);
void OnWriteDone(bool ok) override;
void OnDone() override;
void OnCancel() override;
private:
void NextWrite();
int _mReqEventCount;
int _mCurEventCount;
StockPriceResponse _mResp;
StockRepository _mStockRepo;
};
- NextWrite(): 클라이언트로 전송할 데이터를 생성하고 stream에 쓴다.
- OnWriteDone(): NextWrite()에서 호출하는 StartWrite()에 의해 하나의 정보가 쓰여졌을 때 호출되는 callback이다. 이전의 전송이 성공적으로 되었는지 검사하고 다음 정보를 전송한다.
- OnDone(): Stream 전송 완료를 의미하는 Finish()를 호출하면 불리는 callback이다. 해당 인스턴스의 사용이 종료되었다는 의미이므로 메모리를 해제한다.
Server 구현
class StockServiceImpl final : public StockService::CallbackService
{
public:
...
ServerWriteReactor<::StockPriceResponse> *UpdateStockPrice(
CallbackServerContext *context,
const google::protobuf::Empty *empty) override
{
return new StockPriceWriteReactor(_mEventCount);
}
...
};
gRPC 비동기 호출을 위한 서버는 StockService::Server가 아닌 StockService::CallbackService를 상속받아 구현한다. StockService::Server가 write stream에 전송할 내용을 쓰고 grpc::Status를 반환 하도록 하는 것과 달리 CallbackService는 앞서 정의한 ServerWriteReactor<StockPriceResponse>* type을 반환 하도록 정의 되어있다.
StockPriceReadReactor
StockPriceReadReactor는 클라이언트에서 동작하는 reactor이다.
class StockPriceReadReactor
: public ::grpc::ClientReadReactor<::StockPriceResponse>
{
public:
StockPriceReadReactor(
std::shared_ptr<StockService::Stub> stub, std::shared_ptr<Publisher> pub);
void OnReadDone(bool ok) override;
void OnDone(const ::grpc::Status &s) override;
::grpc::Status Await();
private:
std::shared_ptr<Publisher> _mPub;
::grpc::ClientContext _mContext;
::StockPriceResponse _mResp;
std::mutex _mMtx;
std::condition_variable _mCondVar;
::grpc::Status _mStatus;
bool _mAllDone = false;
};
- OnReadDone(): StartRead() 호출을 통해 서버로 부터 하나의 record인 주식 정보 업데이트를 받을 때 마다 호출되는 callback이다. 이것을 이용해 Observer pattern에서 event publisher가 자신에게 등록된 subscriber들에게 event를 notify하는 코드를 구현할 수 있다.
- OnDone(): 서버로 부터 stream 종료를 받으면 호출되는 callback이다. Await()과 공유되는 condition_variable을 이용해 process가 종료 될 수 있도록 한다.
- Await(): 비동기 호출은 multi threading을 전체 하므로, 이 함수는 서버로 부터 받는 stream이 종료될 때까지 main thread가 종료되지 않고 유지 되도록 해준다.
- mutext와 condition_variable: 위에서 설명한 OnDone()과 Await()이 thread control을 할 수 있도록 해주는 동기화 변수 들이다.
Client 구현
class StockClient
{
public:
...
void updateStockPrice()
{
StockPriceReadReactor reader(_mStub, _mPub);
Status status = reader.Await();
if (status.ok())
{
spdlog::info("PriceListing succeed.");
}
else
{
spdlog::error("Failed to get prices.");
spdlog::error("{}({})", status.error_message(), status.error_code());
}
}
...
};
클라이언트 코드는 StockPriceReadReactor의 instance를 만들고 Await()을 호출해서 서버로 부터 전송이 완료되기를 기다린다. 그럼 서버쪽으로 “주식 가격 주세요”라는 request는 누가 날리냐고? StockPriceReadReactor의 생성자에 다음과 같이 stub에 UpdateStockPrice()를 호출하는 부분이 정의되어 있다.
StockPriceReadReactor::StockPriceReadReactor(
std::shared_ptr<StockService::Stub> stub, std::shared_ptr<Publisher> pub)
: _mPub(pub)
{
::google::protobuf::Empty empty;
stub->async()->UpdateStockPrice(&_mContext, &empty, this);
StartRead(&_mResp);
StartCall();
}
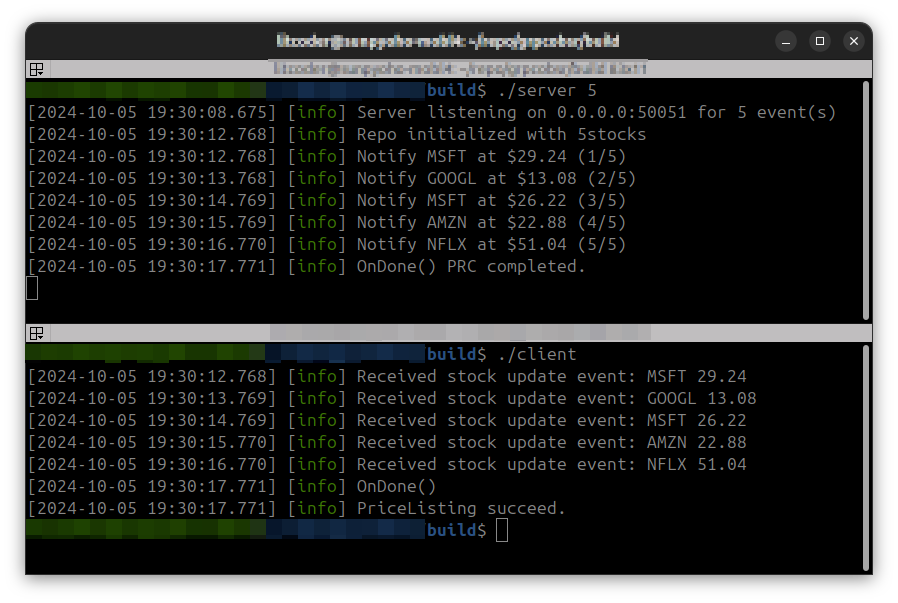
동작 확인
Code repo: https://github.com/litcoder/grpcobsr
References
- gRPC Long-lived Streaming using Observer Pattern: Java로 gRPC의 Observer pattern을 구현한 내용을 설명한 글이다. 사실 본 포스팅의 시작도 원래는 이 구현을 C++로 변경해 보고자 하는 의도였으나 안타깝게도 C++에서 사용할 수 없는 의존성 때문에 많은 부분을 새롭게 작성해야 했다.
- Asynchronous Callback API Tutorial: gPRC에 대한 비동기 호출에 대해 예제를 포함해서 매우 자세히 설명한 글이다. Observer pattern을 직접 언급하고 있지는 않으나 활용도가 높은 Unary, Server-side streaming, Client-side streaming 그리고 Bidirectional streaming을 설명한다.
- gRPC API reference: API들에 대한 설명을 찾아 볼 수 있다. 친절하게 설명된 문서는 아니지만 그래도 없는 것 보다는 뭐…