연동을 위한 설정
#1 먼저 OpenProject에서 연동기능을 전담할 계정을 하나 생성(GitHub Bot)해준다. 그리고 새로운 role(Github integration)을 하나 만들고 View work packages와 Add comments 권한을 준다.
#2 GitHub와 연동하고자 하는 프로젝트에 생성한 전담계정(GitHub Bot)을 추가하고 역할로 GitHub integration을 부여한다.
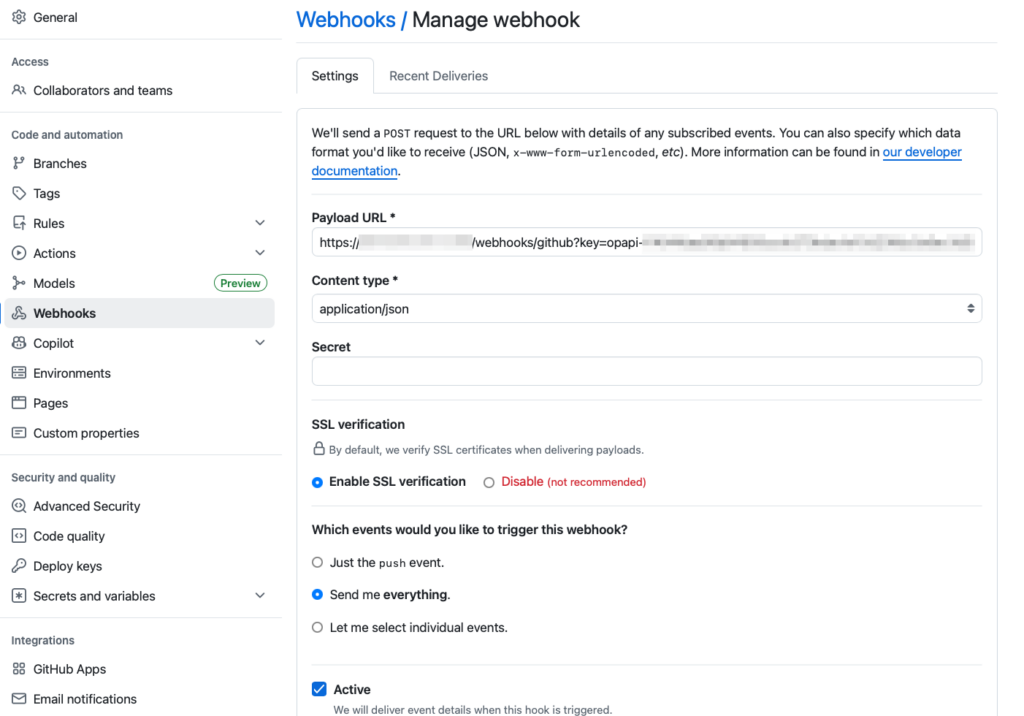
#3 OpenProject에 GitHub 전담 계정(GitHub Bot)으로 로그인해서 Account settings -> Access tokens -> Provider tokens -> API 항목으로 이동해서 access token을 하나 생성한다. 이 token을 복사해서 GitHub의 해당 프로젝트에서 Webhooks 항목에 등록하고, “Send me everything” 권한을 설정한다.
#4 OpenProject의 프로젝트 설정에서 GitHub Module을 활성화 한다.
Project settings -> Modules -> GitHub
연동 하는 방법
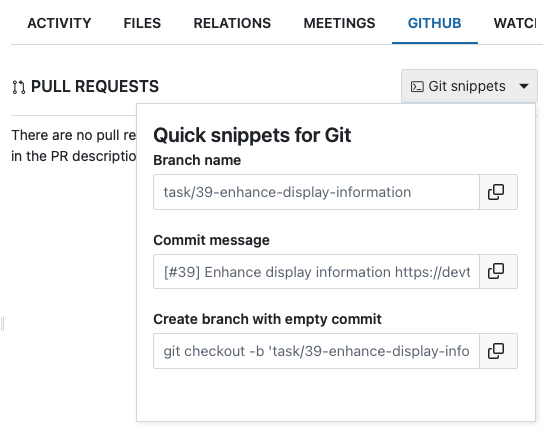
GitHub module이 활성화 되었다면 각 티켓의 항목에 위와 같이 GITHUB 항목이 나타나고 “Git snippets”를 눌렀을 때 사용 할 수 있는 Git 명령어 들의 preset 들이 보인다.
“Create branch with empty commit“을 눌러서 복사한 후 git repository에서 붙여 넣으면 새로운 branch가 생성되면서 비어 있는 commit이 하나 생기는데, 이 commit에 수정사항을 기록해서 PR을 생성하면 PR의 Open/CI(pass/fail)/Merged 등의 상태가 OpenProject ticket에 연결되어 자동으로 추적된다.
참조
OpenProject – GitHub integration 문서