망했다! Litghtsail의 Ubuntu 배포판이 너무 오래전 것이라 콘솔에 접근해서 조심스럽게 screen session도 새로 만들어 가면서 업그레이드를 했는데 끝나고 나니 SSH가 안된다. 아마도 중간에 SSH관련 환경설정을 파일을 변경할 것인지 묻는 선택메뉴가 나왔는데, 현재 설정을 그냥 쓰겠다고 했던게 문제인것 같다. 다행히 blogging service는 잘돌아 가고 있지만 SSH가 안되면 서버관리를 할 방법이 없는데…
Workaound
다행히 세상은 생각보다 넓고 인간은 같은 실수를 반복하기에 이전에 같은 실수를 한 사람의 비슷한 경험을 정보의 바다에서 찾을 수 있었다 (SSH stops working after upgrade to Ubuntu 18.04 on AWS Lightsail). 대충 Ubuntu 18.04 LTS로 올라가면서 SSH 환경설정 파일에 변경이 있었는데 메인테이너 버전을 적용하지 않으면 문제가 되는가 보다. 이 포스팅은 위의 링크에 있는 내용을 기준으로 정리한 것이다. (Lightsail 한정이고 EC2를 사용하고 있다면 아래와 같이 번거로운 작업을 할 필요가 없다고 한다)
순서 요약
- SSH접속이 안되는 instance로 부터 스냅샷을 하나 만든다.
- 스냅샷의 시작 스크립트에 ssh 환경설정을 수정하는 명령어를 넣고 새로운 인스턴스를 만든다.
- 잘 되면 새로운 인스턴스를 고정 IP에 연결하고 이전 인스턴스를 지운다.
스냅샷 생성
SSH 접속이 안되는 인스턴스로 부터 스냅샷을 하나 만든다. 관리 -> 스냅샷 수동 스냅샷 아래의 ‘+ 스냅샷 생성’을 클릭.
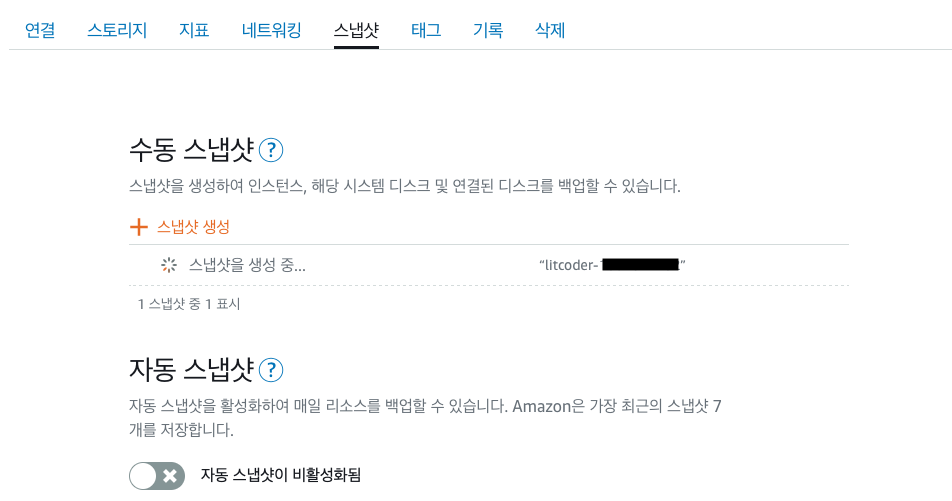
생성이 완료될 때까지 조금 기다렸다가 이 스냅샷으로 부터 새로운 인스턴스를 하나 만든다.
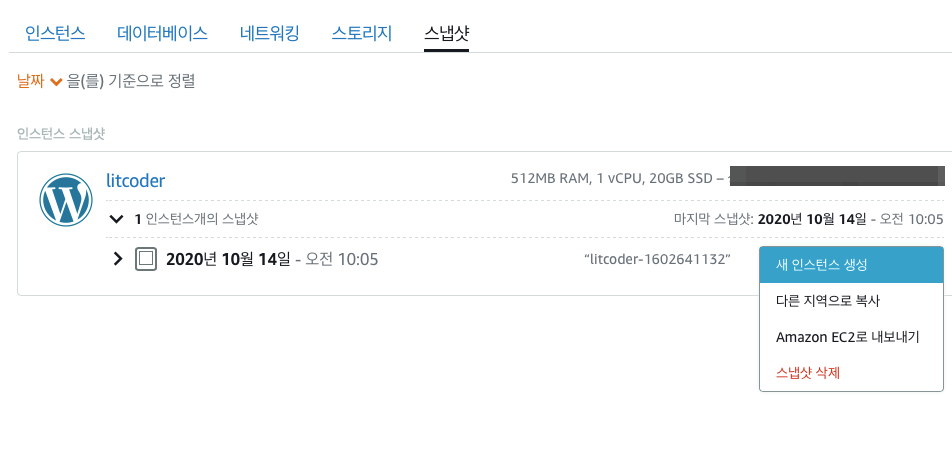
시작 스크립트를 추가하고 인스턴스를 실행
새 인스턴스 생성 메뉴에 보면 “시작 스크립트”를 넣는 곳이 있는데 이곳을 선택하고 ssh config를 변경해 줄 다음의 sed 명령어를 입력한다.
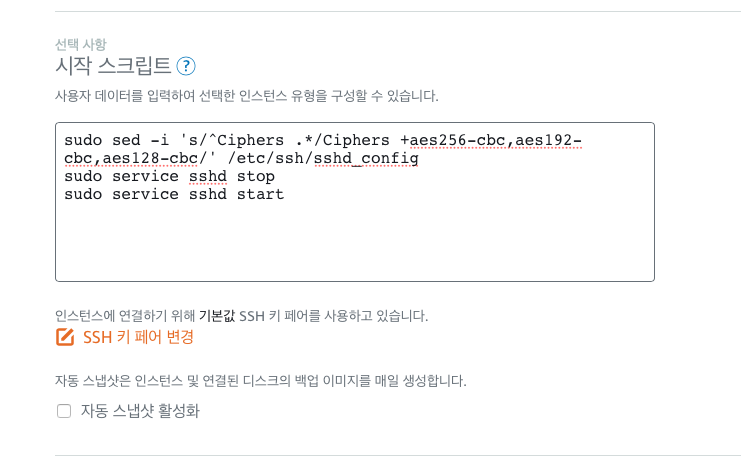
sudo sed -i 's/^Ciphers .*/Ciphers +aes256-cbc,aes192-cbc,aes128-cbc/' /etc/ssh/sshd_config sudo service sshd stop sudo service sshd start
그리고 나서 인스턴스를 실행하면 처음에는 여전히 SSH 접속이 되지 않는데, 꽤 오랜 시간 (10~20분)이 지나고 나서야 가능해 진다.
고정 IP 변경과 정리
네트워킹 -> Static IP에서 고정 IP를 분리하고 새로운 인스턴스에 새로 연결해 준다.
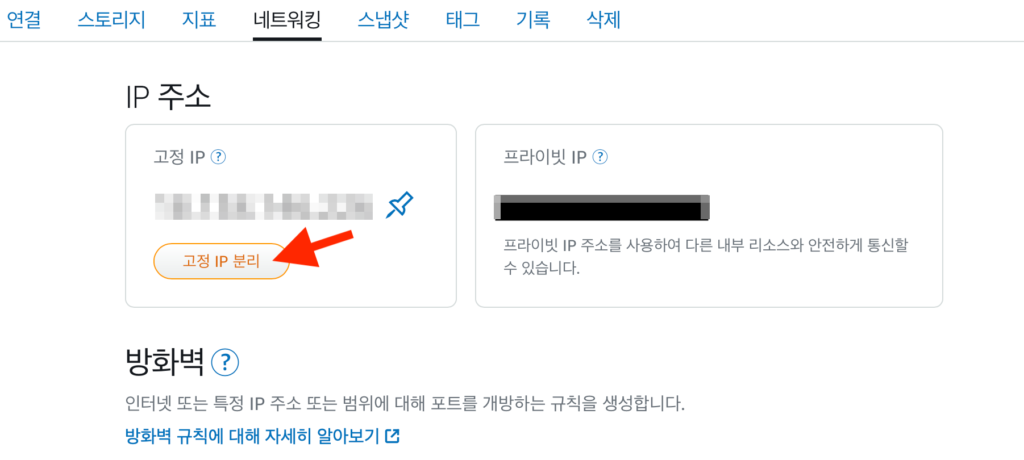
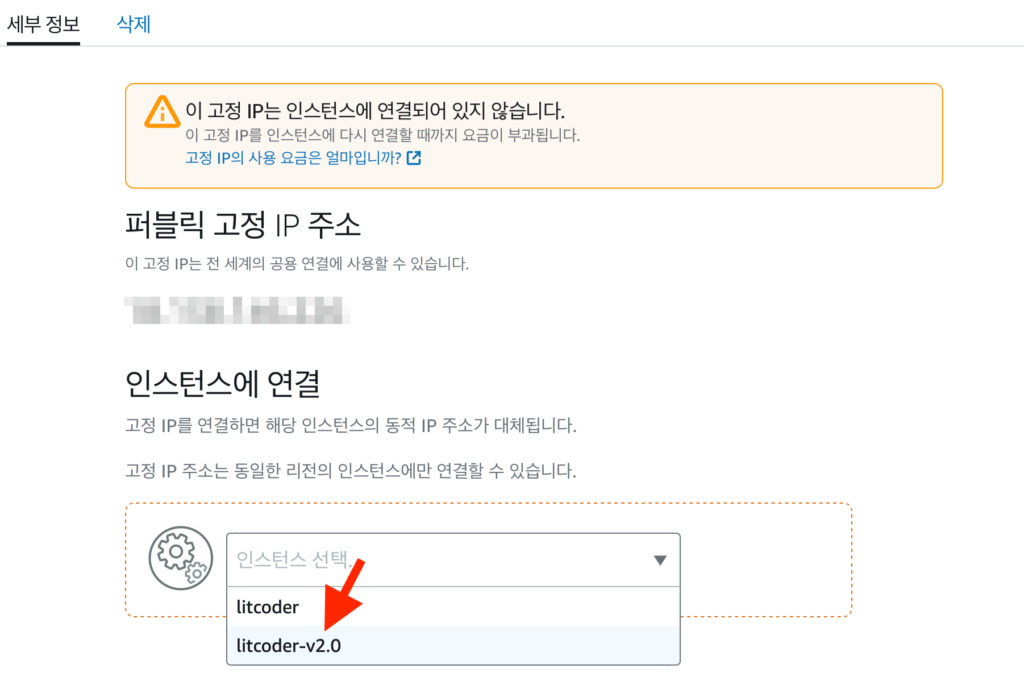
새로운 인스턴스를 고정 IP에 할당 한 후 기존 서버를 끄고 도메인에 접속해서 잘 돌아가는 지 확인한 후 스냅샷과 기존 인스턴스를 지워준다. 스냅샷 생성 기능은 예전에 한 번 백업용으로 좋겠다 싶어서 만들어 봤다가 추가 요금이 나온적이 있다. 🙁
결론
다음 부터는 이미지를 업데이트 하고 싶을 땐 먼저 백업을 만들어서 작업 및 확인하고 최종으로 IP를 변경 하도록 하자.