gRPC에서 Observer pattern을 구현하는 예제를 고민했던 적이 있었는데(gRPC를 이용한 Observer Pattern) 알고보니 gRPC에서는 ReadReactor / WriteReactor 보다 간단하게 object의 상태 변경을 감지할 수 있는 메커니즘을 제공하고 있었다. gRPC를 이용한 Observer pattern 구현 예제를 찾기 어려웠던 이유가 어쩌면 그런 복잡한 패턴 없이도 구현이 가능하기 때문이었는지도 모르겠다.
이 포스팅에서는 Stream을 통해 변경되는 값들을 subscribe하는 간단한 예제를 Rust로 구현해 본다. gRPC의 Rust 구현체인 tonic과 proto compiler인 prost, 비동기 처리를 위해 tokio를 사용했다.
Proto file – stockprice.proto
랜덤하게 생성된 주가 정보를 gRPC로 구독하는 간단한 서비스 예제를 가정해 보자. Proto file은 UpdateStockPrice()를 정의하고 호출되면 StockPriceResponse의 stream을 받아오도록 다음과 같이 구성한다.
syntax = "proto3";
package stockservice;
import "google/protobuf/empty.proto";
message StockPriceResponse {
string symbol = 1;
double price = 2;
uint64 sequence = 3;
}
service StockService {
rpc UpdateStockPrice(google.protobuf.Empty) returns (stream StockPriceResponse);
}
Server
StockServiceImpl 구조체를 선언하고 서비스를 제공하기 위한 StockService를 다음과 같이 구현한다.
// Server 구현체
struct StockServiceImpl;
// tokio_stream을 이용해서 gRPC stream을 구현.
type StockStream = Pin<Box<dyn Stream<Item = Result<StockPriceResponse, Status>> + Send>>;
#[tonic::async_trait]
impl StockService for StockServiceImpl {
type UpdateStockPriceStream = StockStream;
async fn update_stock_price(
&self,
_request: Request<()>,
) -> Result<Response<Self::UpdateStockPriceStream>, Status> {
// 1초 간격으로 stock price 생성
let mut interval = tokio_stream::wrappers::IntervalStream::new(tokio::time::interval(
Duration::from_secs(1),
));
// Stream으로 전송할 데이터를 생성하고 yield로 반환.
let output = async_stream::stream! {
let mut rng = SmallRng::from_os_rng();
let mut sequence: u64 = 0;
// 매 interval마다 순번을 증가시키고 랜덤 주가를 생성해 클라이언트로 전송
while interval.next().await.is_some() {
sequence += 1;
let p = generate_stock_price(&mut rng, sequence);
yield Ok(p);
}
};
Ok(Response::new(
Box::pin(output) as Self::UpdateStockPriceStream
))
}
}
이 코드에서 핵심은 async_stream::stream!() 매크로로 데이터를 전송할 데이터임을 정의하고, while / yeild로 data를 전송하는 다음의 부분이다. 이 부분에서 데이터를 갱신하고 stream에 지속적으로 update 시킨다.
let output = async_stream::stream! {
...
// 매 interval마다 순번을 증가시키고 랜덤 주가를 생성해 클라이언트로 전송
while interval.next().await.is_some() {
// Data 생성 및 전송
...
yield Ok(p);
}
};
Client
Server에 비해 Client 쪽은 비교적 구현이 간단한데, prost가 proto file로 부터 생성해 준 StockServiceClient를 이용해서 stream을 생성하고, 이 때 반환받은 stream으로 부터 계속 데이터를 읽어 주면된다.
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
let mut client = StockServiceClient::connect("http://[::1]:50051").await?;
// grpc 서비스 stream 생성.
let mut stream = client
.update_stock_price(Request::new(()))
.await?
.into_inner();
// stream에서 데이터를 받아서 화면에 출력.
while let Some(update) = stream.message().await? {
println!(
"[{}] {}: {:.2}",
update.sequence, update.symbol, update.price
);
}
Ok(())
}
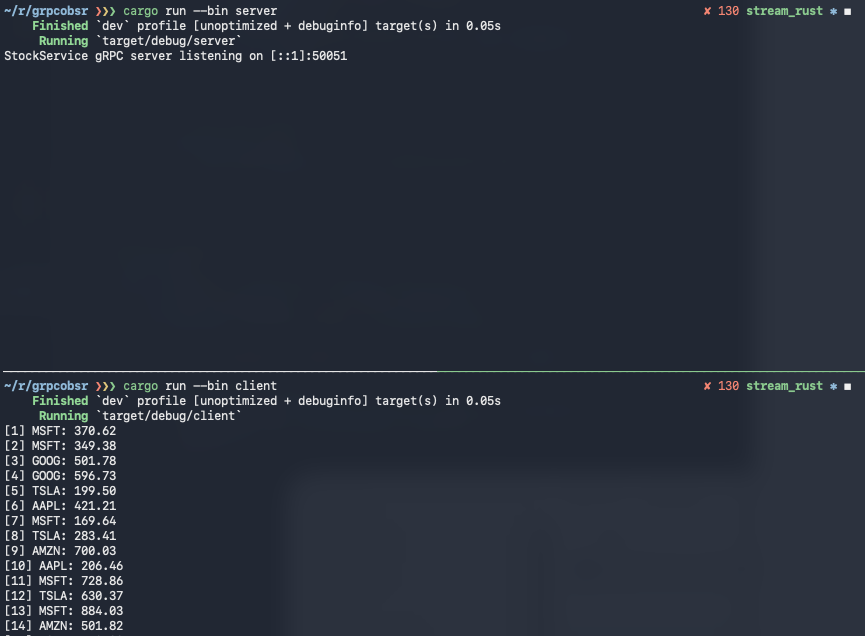
코드 위치 및 수행결과
전체 구현 코드는 다음 위치에 있다. https://github.com/litcoder/grpcobsr/tree/stream_rust